8-7 哈希表(散列表)
简介
哈希表是一种使用哈希函数组织数据的数据结构,它支持快速插入和搜索。
原理
哈希表(又称散列表)的原理为:借助 哈希函数,将键映射到存储桶地址。更确切地说,
首先开辟一定长度的,具有连续物理地址的桶数组;
当我们插入一个新的键时,哈希函数将决定该键应该分配到哪个桶中,并将该键存储在相应的桶中;
当我们想要搜索一个键时,哈希表将使用哈希函数来找到对应的桶,并在该桶中进行搜索。
作者:力扣 (LeetCode)
链接:https://leetcode-cn.com/leetbook/read/hash-table-plus/kd67i/
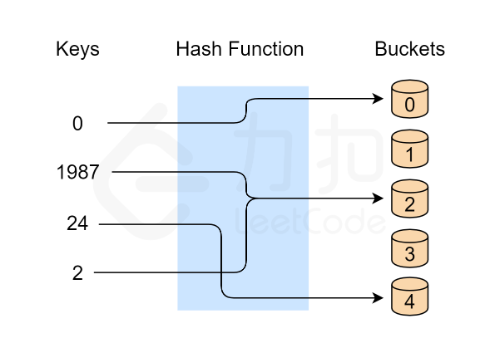
可以联想到cache的工作原理。
负载因子
实际利用桶的个数与桶的总数 的比值,称为负载因子,反映了哈希表的装满程度。负载因子太低了,会使得大量存储空间被浪费,负载因子太高了,出现哈希冲突的概率就会难以接受。比较合理的负载因子是 0.7,如果数据量是 7,则会创建 10 个桶,以此类推。随着插入的数据量的增加,计算机会逐渐增加桶的个数,并选择合适的哈希函数,使得数据经过映射之后能均匀地分布在桶中。
哈希冲突
不同的key被哈希函数映射到了同一个桶中,这时就出现了哈希冲突。为处理哈希冲突,常用以下几种方法。
线性试探法
插入
如果通过哈希函数映射到某个桶,发现这个桶已经被占用了,那么就可以按地址往后寻找,直到找到一个空的桶(如果找到了哈希表最后一个地址,就从表头继续)。查询
将查询的key带入哈希函数,得到对应的映射,比对这个映射处桶的key是否为要查询的,如果不是,那么往后面查找,直到找到能对上的为止。删除
将对应位置标记位delete
链地址法
顾名思义,发生哈希冲突时,将同一个桶里的元素串成一个链表,哈希表内只存储链表表头(第一个入表的元素)以及下一个元素的指针。
再哈希法
比如双重哈希法,当发生冲哈希突时,使用另一个哈希函数来避免冲突。
公共溢出区法
建立一个公共区域,将因发生哈希冲突而无法入表的元素,都放在这个公共区域。
哈希集合的简单实现
简单实现哈希集合的功能,需要实现的功能有
add(int key),将key加入哈希集合中;
remove(int key),将key从哈希集合中移除;
contains(int key),key是否在哈希集合中。
1 | class MyHashSet { |
哈希映射的简单实现
简单实现哈希映射的功能,需要实现的功能有
put(int key, int value),将key:value加入哈希表中;
remove(int key),将key从哈希表中移除;
get(int key),返回key对应的value。
1 | class MyHashMap { |
因为是使用的数组来存储,所以在删除元素的时候,可以将当前要删除的元素和数组中最后一个交换,再删去最后一个元素,这样能够提升速度